Focal Visual-Text Attention for Memex Question Answering
1Carnegie Mellon University, 2Google AI, 3University of Massachusetts, 4Facebook Research
In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).
Introduction
Recent insights on language and vision with neural networks have been successfully applied to simple single-image visual question answering. However, to tackle real-life question answering problems on multimedia collections such as personal photo albums, we have to look at whole collections with sequences of photos. This paper proposes a new multimodal MemexQA task: given a sequence of photos from a user, the goal is to automatically answer questions that help users recover their memory about an event captured in these photos. In addition to a text answer, a few grounding photos are also given to justify the answer. The grounding photos are necessary as they help users quickly verifying the answer. Towards solving the task, we 1) present the MemexQA dataset, the first publicly available multimodal question answering dataset consisting of real personal photo albums; 2) propose an end-to-end trainable network that makes use of a hierarchical process to dynamically determine what media and what time to focus on in the sequential data to answer the question. Experimental results on the MemexQA dataset demonstrate that our model outperforms strong baselines and yields the most relevant grounding photos on this challenging task.
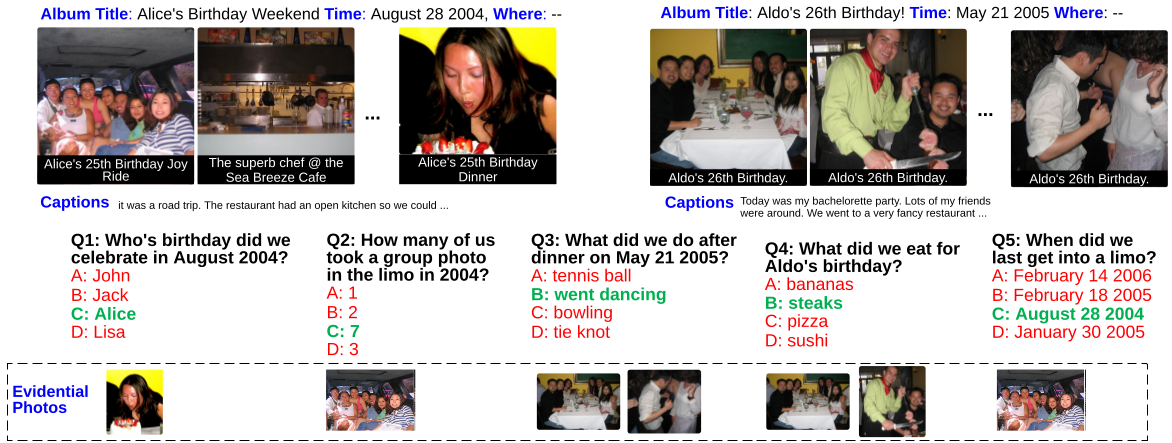
Figure: Questions and four-choice answer in MemexQA. From the top to bottom are album metadata, photos from 2 albums, titles and captions, questions, answer choices, and evidential photos. The green choice denotes the correct answer.
Explore more...
Dataset
Table: Comparison of the representative VQA datasets and our MemexQA dataset.
Here we provide download links for the question-answer pairs with candidate answers for each question. The candidate answers are mainly automatically generated. We also provide raw images of the albums as well as image features.
Current version: 1.1
 qas.json
qas.json (
Pretty print version) The question-answer pairs in JSON format. Total 20563 QAs.
album_info.json
Album metadata in JSON format.
test_question.ids
Question ID list for test set.
Photo collection:
shown_photos.tgz (7.5GB)
The 5k photo collection used in the training and evaluation of our models.
photos_inception_resnet_v2_l2norm.npz
Image features for this photo collection.
Additional data:
gcloud_concepts.p
Visual concepts in the photos by Google Vision API.
gcloud_ocrs.p
OCR transcriptions from the photos by Google Vision API.
all_photo.ids
All photo IDs from the
Video Storytelling dataset used in the data collection. Please download the original images from their website.
Terms of use: by downloading the image data you agree to the following terms:
-
You will NOT distribute the above images.
-
Carnegie Mellon University makes no representations or warranties regarding the data, including but not limited to warranties of non-infringement or fitness for a particular purpose.
-
You accept full responsibility for your use of the data and shall defend and indemnify Carnegie Mellon University, including its employees, officers and agents, against any and all claims arising from your use of the data, including but not limited to your use of any copies of copyrighted images that you may create from the data.