Introduction
Recent insights on language and vision with neural networks have been successfully applied to simple single-image visual question answering. However, to tackle real-life question answering problems on personal collections, we have to look at whole collections with sequences of photos or videos. When answering questions from a large collection, a natural problem is to identify snippets to support the answer. In this paper, we describe a novel neural network model called Focal Visual-Text Attention network (FVTA) for collective reasoning in personalized question answering, where both visual and text sequence information such as images and text metadata are presented. FVTA introduces an end-to-end approach that makes use of a hierarchical process to dynamically determine what media and what time to focus on in the sequential data to answer the question. FVTA can not only answer the questions well but also provides the justifications which the system results are based upon to get the answers.FVTA achieves state-of-the-art performance on the newly released MemexQA dataset and the MovieQA dataset.
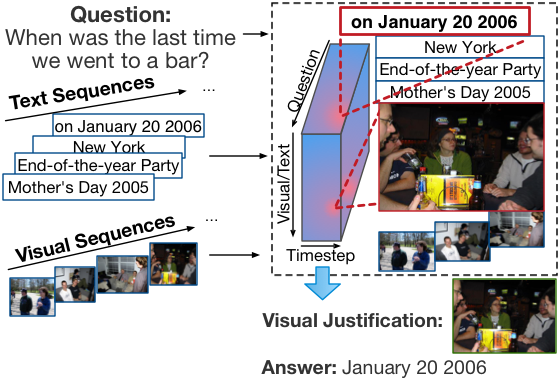
Figure: An overview of Focal Visual-Text Attention (FVTA) model. For visual-text embedding, we use a pre-trained convolutional neural network to embed the photos and pre-trained word vectors to embed the words. We use a bi-directional LSTM as the sequence encoder. All hidden states from the question and the context are used to calculate the Focal Visual-Text Attention (FVTA) tensor. Based on the FVTA attention, both question and the context are summarized into single vectors for the output layer to produce final answer. The output layer is used for multiple choice question classification. Note that the text embedding of the answer choices are also used as input.
